* 모두연 박은수님, Pytorch로 시작하는 딥러닝의 내용들을 공부하면서 정리한 내용입니다. https://www.youtube.com/watch?v=mG6N0ut9dog
1) Data 준비
Text는 연속된 문자 또는 연속된 단어의 형태로 되어있는 순차 (Sequence) 데이터이다. 그렇기 때문에 RNN 같은 순차 모델은 자연어 처리, 문서 이해, 요약, 감성 분류에 활용되고 있다. RNN에서는 이러한 순차 데이터가 가진 feature를 파악하는데 유용하다. 하지만 모델도 기계에서 구동해야 하기 때문에 이러한 텍스트 데이터를 숫자로 변환 (벡터화) 해야 한다. 이때 텍스트의 가장 작은 단위를 토큰 (Token)이라고 하고 이렇게 변환하는 것을 Tokenization이라고 한다. 그리고 이 토큰을 벡터에 대응시키는 작업으로 사용되는 방법은 One-Hot Encoding, Word Embedding이 있다.
일반적인 Tokenization 방법으로 spaCy 또는 split, list를 이용해 문자를 단어로 단어를 글자로 바꾼다. N-그램은 글자나 단어 단위가 아니라 묶음으로도 벡터화 할 수 있다. 이러한 방식으로 Feature space를 개선할 수도 있지만, 순서 정보를 잃어버릴 수 있다. 그렇기 때문에 이것 대신 RNN에서는 주로 사용하지 않는다.
그다음으로 벡터화 방법으로 사용되는 One-hot Encoding, Word Embedding 중 One-hot Encoding은 단어의 길이 (N)을 기준으로 N 길이의 벡터를 만들고 각각의 토큰에 번호를 부여한다. 다만 (0100000)처럼 요소의 값만 1이고 나머지는 0으로 처리한다. 이러한 특징 때문에 데이터가 대부분이 0이 되어 버리고 단어 수가 증가할수록 문제가 될 수 있다. Word Embedding은 부동 소수점 형태의 수로 채워진 Dense Vector로 이를 표현하고 의미가 비슷한 단어일수록 비슷한 값을 가지게 하여 공간에서 근처에 배치되게 한다. (https://wikidocs.net/33520)
2) RNN Model
RNN은 데이터의 순서 특성을 가장 잘 이용하는 모델로, 인간처럼 자연어 등을 순차적이고 반복적으로 처리하는 구조를 갖고 있다. 그리고 이러한 특성 덕분에 길이가 다른 벡터를 사용할 수 있고, 아래 이미지처럼 output의 크기도 다양하다. One to Many의 경우 이미지가 들어왔을 때 글을 생성할 수도 있고 (Image Captioning), Many to one은 어떤 단어들의 요약, Many to many는 Machine Translation 등으로 활용될 수 있다.

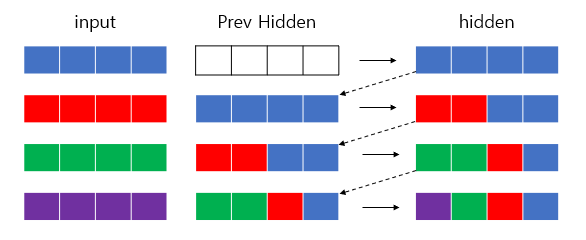
위의 이미지에서처럼 RNN 모델의 한 셀에서 State vector (초록), Output vector (파랑)를 출력한다. 이 Previous Hidden Vector를 사용하는 이유는 아래 이미지로 쉽게 이해가능하다. 이전 input을 기준으로 계속 넣어준다면 모든 데이터를 알기어렵겠지만, Previous Hidden 방식으로 최종 Output에 모든 input data들을 다 함축해 가지고 있는것을 볼 수 있다. 이처럼 RNN은 이전의 Hidden data를 포함하게끔 하는 딥러닝 뉴럴 네트워크 구조이다. (첫 Hidden은 0으로 초기화함). 만약 input - prev_Input 관계로 되어있었다면 마지막은 보라2/초록2이 될 것 이다.
수식적 설명: https://dacon.io/forum/406031
RNN의 학습 과정은 예를 들어 many-to-many 모델에서 파란 셀의 결과 (y)값들을 기준으로 loss를 각각 계산하고, 그 값들을 모두 합친 Loss (Cross entropy)의 크기를 줄여주는 방향으로 weight를 줄여주는 방식으로 학습을 하게 된다. 이 과정에서 SGD 등의 방식을 사용하게 된다.
3) LSTM Model
크기가 큰 데이터를 사용할 때 RNN에서 발생하는 vanishing gradients, gradient explosion과 같은 문제를 해결하기 위한 변형 알고리즘이 LSTM이다. 예를 들어 위의 이미지를 보아도 길이가 긴 문장을 사용할 때에는 RNN의 기본 모델로는 초반 부분에 대한 데이터를 모두 다 기억하고 있기 어려운 부분이 있다. LSTM이라는 이름에서 알 수 있듯이 손실되는 데이터들을 메모장에 필기하듯이 저장해두는 방식으로, 내부셀에 선형 레이어 대신 각각에 작은 네트워크를 만들어 장/단기간으로 정보를 기억할 수 있는 모델을 만들었다.

이 또한 nn.LSTM pytorch layer로 구현이 되어있으며 자세한 수식적 내용은 https://elham-khanche.github.io/blog/RNNs_and_LSTM/를 참고하면 된다. 이미지에서 보면 LSTM에서 윗 부분 (C)에 해당하는 부분이 메모리에 해당하는 부분이고, O로 표시된 작은 네트워크 (Forget gate)에서 활성화 함수로 활용되며 메모리의 값들에서 버릴 것, 유지할 것을 선별하는 작업을 한다고 보면된다. + 기호에서는 내용을 메모리에 update를 하게된다.
4) 마무리
어느 모델이 그렇듯 LSTM도 한계가 있다. RNN의 셀마다 전달되는 벡터에 모든 내용이 저장되고 업데이트 되는데, 이는 비효율적이므로 메모리에 넣어두고 필요할때마다 만드는 방식을 사용하는 Attention과 더 나아가 Self-Attention을 사용하는 Transformer (Leo Dirac)이 주목을 받았고 최근에 또 새로운 방식이 나온듯하다. 이 부분에 대해서는 GAN 이후에 좀더 공부해보려한다.
https://synergy-ai.github.io/2021-03-23-Transformer-is-all-you-need/
'Programming > Deep Learning' 카테고리의 다른 글
| 6. Convolution Neural Network (CNN) (0) | 2021.02.04 |
|---|---|
| 5. 머신러닝 Workflow (0) | 2021.02.01 |
| 4. 머신러닝 입문 (0) | 2021.01.22 |
| 3. 신경망 구조 (0) | 2021.01.19 |
| 2. 신경망 구성 요소 (0) | 2021.01.13 |